Unsupervised Machine Learning...
Let's analyze the cluster data and implementation on some of the algorithms of the unsupervised machine
learning
techniques via Python...
 Fig. Unsupervised Machine Learning
Fig. Unsupervised Machine Learning
Let's study the Python codes in unsupervised ways .....
So, we are working in Python code along with pandas, seaborn, numpy etc. libraries to determine
pattern
inside unlabeled data without humanoid intervision
, we'll visualize the data and analyze the cluster via various algorithms in the search of
achieving higher accuracy.
Now let's discuss little bit about Unsupervised learning, it is a genre of machine learning and
artificial
intelligence that uses untagged datasets to learn algorithms for
getting required outcomes via recognize patterns or similarities or differences in information , we ca
say. Unlike supervised learning,
unsupervised learning algorithms
are not having labeled data to learn the relationship between the
input and the outputs as we are seeing through fig. visually.
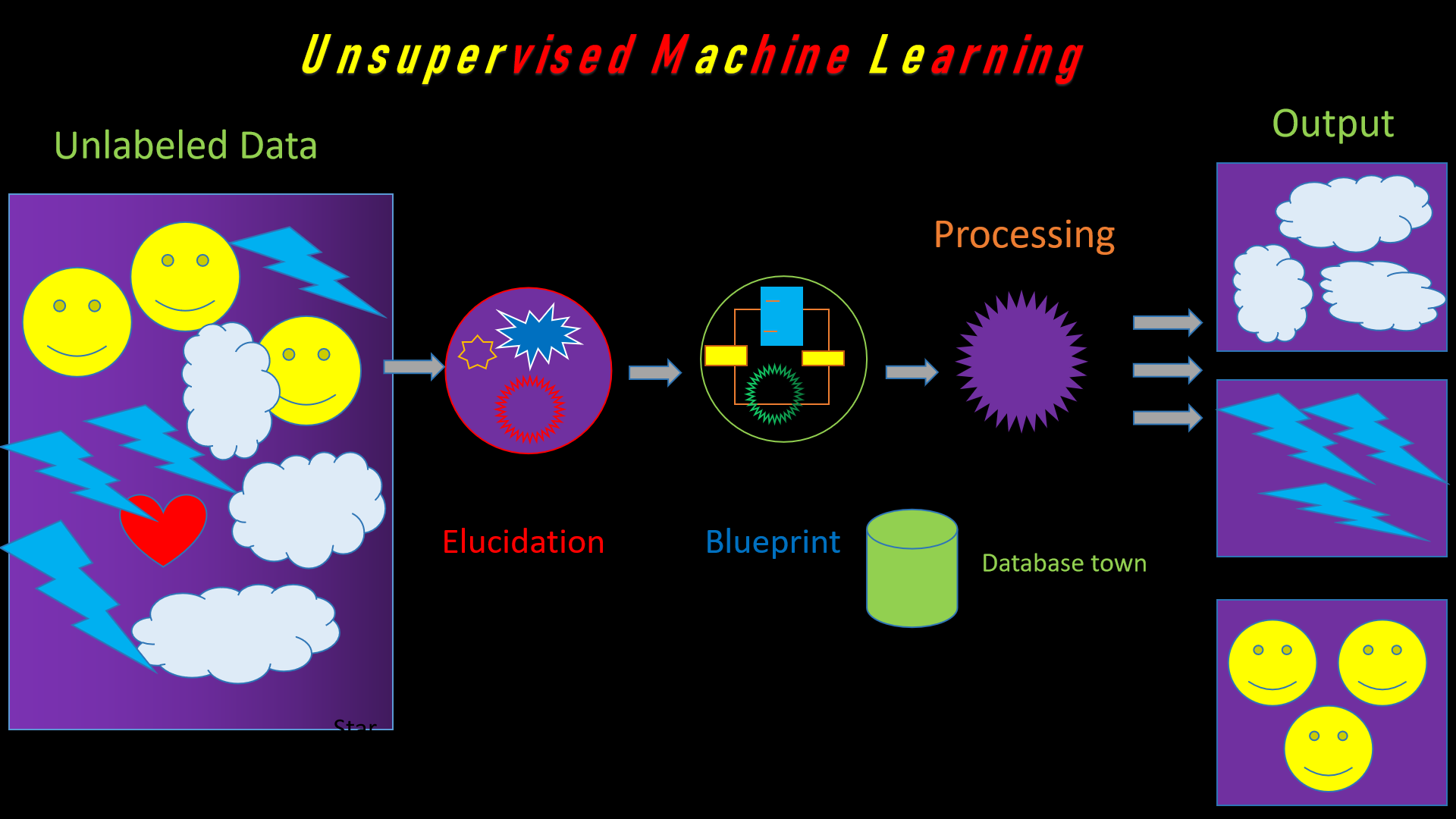 Fig. Mechanism of Unsupervised Machine
Learning
Fig. Mechanism of Unsupervised Machine
Learning
So the question arises here, What is unsupervised learning?
As per knowledge, Unsupervised learning is a kind of machine learning technique which generally utilizes
artificial intelligence
algorithms needed to pick out patterns through data cluster which generally not even categorized nor yet
docket respectively.
Unsupervised learning models don't need humanoid supervision while searching the pattern on data sets,
making it an ideal ML
technique for discovering patterns, groupings and differences in unstructured data. It's well-suited for
processes such as customer segmentation, exploratory data analysis or image recognition.
In conclusion, unsupervised learning algorithms can classify, label and group the data points contained
within data
sets without requiring any external guidance in performing that task. In other words, unsupervised
learning allows a system to identify patterns within data sets on its own.
If we talk about unlabeled data, then it comprise of input attribute said to be cluster or
predictors and finding the structures and
correlate in between the data or finding the hidden patterns or targets respectively. What is
unsupervised
machine learning used for?...Basically our model's aim is to
search the patterns and correlation amidst the input attributes and the output docket, permits it to
exploratory data and construct meticulously prediction from hidden features by using measure of
similarities beside the cluster data respectively.
Algorithms
Let's study some of the algorithms present in unsupervised machine
learning .....
1. Clustering
In general, clustering is an explodatory approach which is generally used to recognize the similarities
on given
cluster, is one kind of unsupervised learning. AI programmed with clustering algorithms categorizes data
points into various groups based on their commonalities or differences. Some clustering algorithms only sort
each color smiley into one group, while others may classify the same color smiley as belonging to two or
more
overlapping groups as we can see in fig. also.
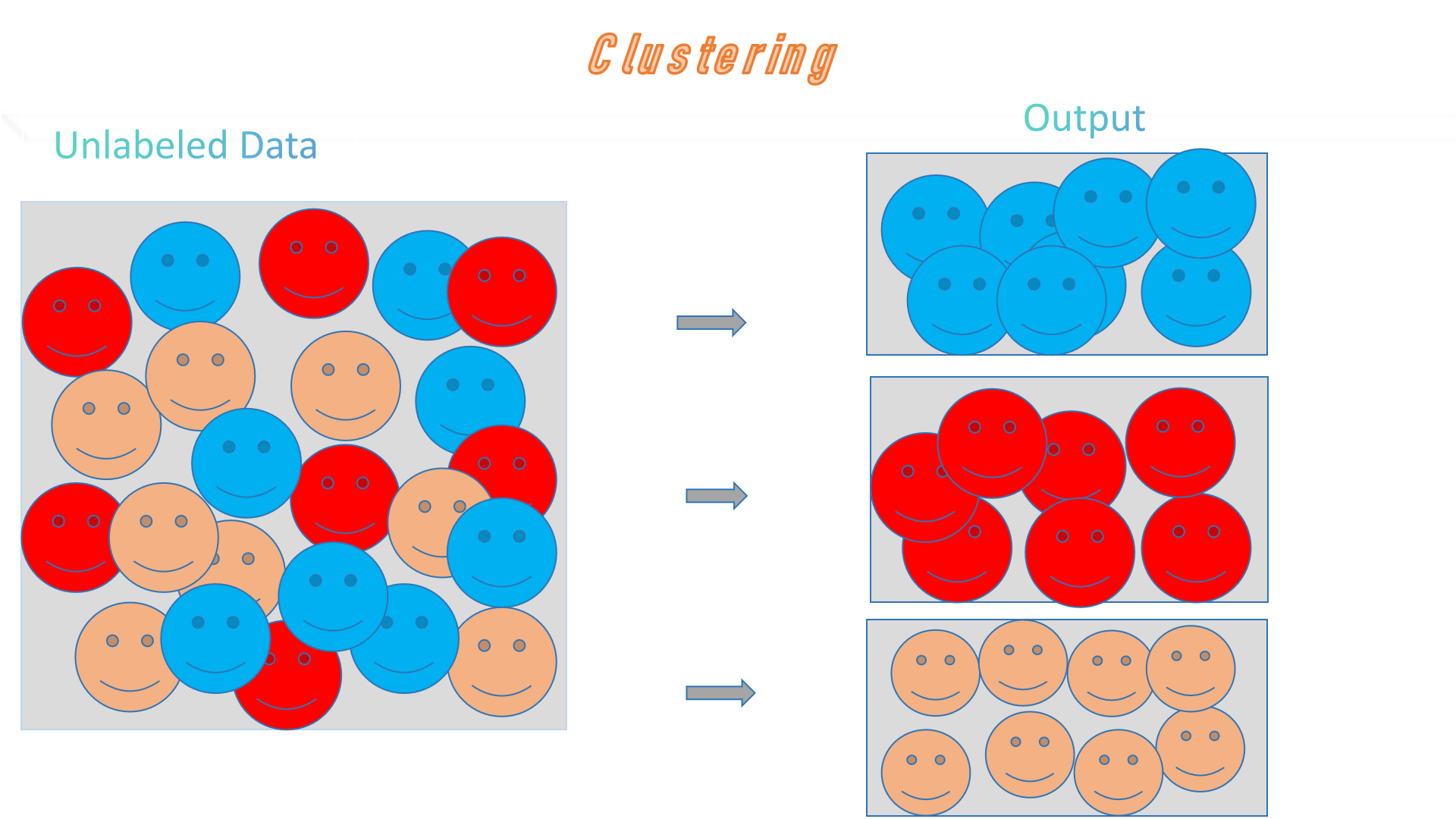 Fig. Clustering : Shorting the different color smiley in separate box
Fig. Clustering : Shorting the different color smiley in separate box
Clustering is a popular type of unsupervised learning approach. You can even break it down further into
different types of clustering
1. Clustering
In exclusive clustering, generally features are collected thatswhy any feature point exclusively be
connected to one cluster.
Overlapping clustering- Here, A pale cluster having a uni feature point be connected to multiple clusters
with
assorted degrees of belonging respectively.
2. Hierarchical clustering
A type of clustering in which groups are created such that similar instances are
within the same group and different objects are in other groups.
Probalistic clustering: Clusters are created using probability distribution.
Let's be familiar with some of the examples of Clustering ::
1. Analyze document clustering.
2. Analyze fraud detection .
3.Assess fake news detection.
4. customer segmentation, etc.
Let's implement the Python codes in unsupervised ways .....
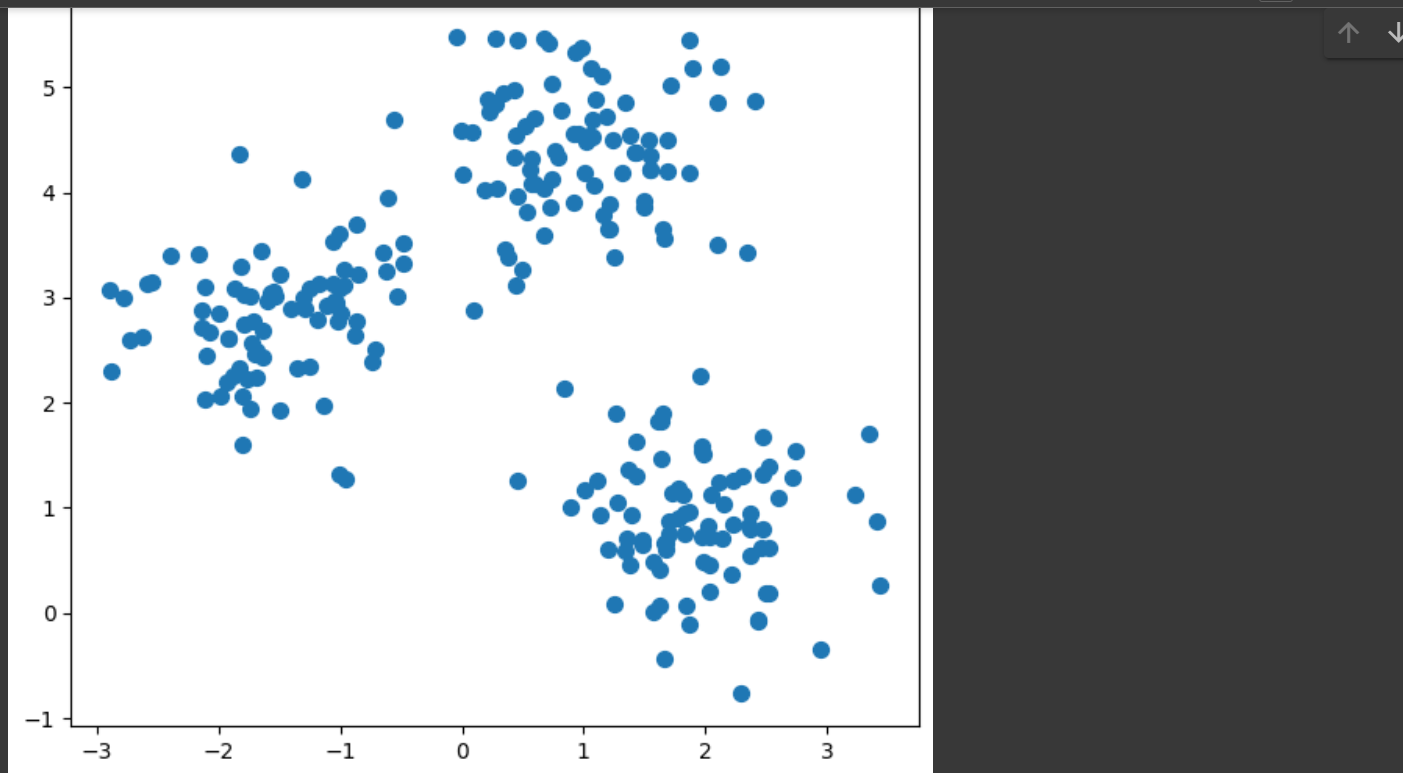
K-Means: Numpy First, we will import the necessary python packages and create a 2-dimensional data set using
Scikit-learn’s make_blob function. For this article, we will be generating 300 data points that are
distributed amongst 4 clusters. The generated data is shown below.
We can see that there are 4 distinct clusters in the sample, with a slight overlap between outlying data
points in each cluster. Next, we will initiate two hash maps. One will keep track of the cluster centroids,
and the other will keep track of the data points in each cluster.
The final three functions put it all together by providing a means to check if the model has converged, to
have a master training function, and to visualize the model results.
# Load the data
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
n_clusters = 3
n_samples = 250
epochs = 111
X, y_true = make_blobs(n_samples=n_samples, centers=n_clusters, cluster_std=0.60,
random_state=0)
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1], s=40)
plt.title("Data Points")
plt.show()
result ::
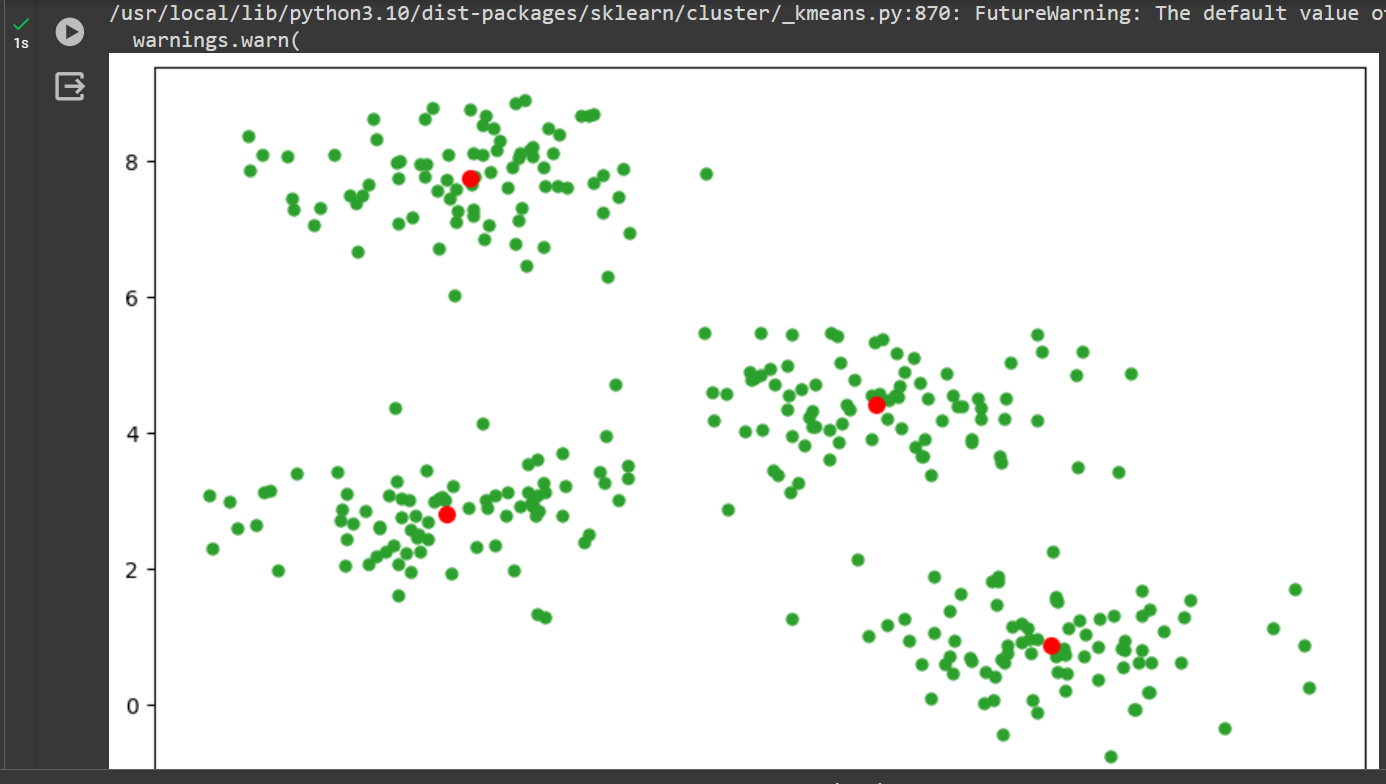
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
n_clusters = 4
n_samples = 333
epochs = 111
X, y_true = make_blobs(n_samples=n_samples, centers=n_clusters, cluster_std=0.60, random_state=0)
kmeans = KMeans(n_clusters=n_clusters, random_state=0, max_iter=epochs).fit(X)
fig, axis = plt.subplots(figsize=(10, 6))
axis1 = plt.subplot(1, 1, 1)
axis1.scatter(X[:, 0], X[:, 1], c='tab:green', s=25)
for k in kmeans.cluster_centers_:
axis1.scatter(k[0], k[1], c='red', s=50)
axis1.set_title("Scikit-Learn K-means Results")
plt.show()
result ::
Now, the advantages of using existing libraries, in which they are optimized to reduce training time, they
frequently
arises with various parameters, and they need little bit code to implement. Scikit-learn also contains
various
other machine learning models, and accessing different models is done using a consistent syntax.
In the above coding, we implement the same k-means clustering algorithm.
Let's see certain admired Clustering algorithms which comes under unsupervised learning ::
1. K-Means Clustering
3. Mean-Shift Clustering
4. Hierarchical Clustering
5. Expectation–Maximization (EM) Clustering using Gaussian
Mixture Models (GMM) or EM GMM
6. Deep Neural Networks
2. Association mining rule
If we discuss about sassociation rule, it is a kind of unsupervised learning algorithm, we can say,
and utilized in machine learning to recognize the pattern . Association rule emphasizes discovering the
connections between data points. AI trained in association rule might find relationships between data points
within one group or relationships between various data sets. For example, this type of unsupervised learning
might try to determine if one variable or data type influences or directly causes another variable
See the graphical representation ::
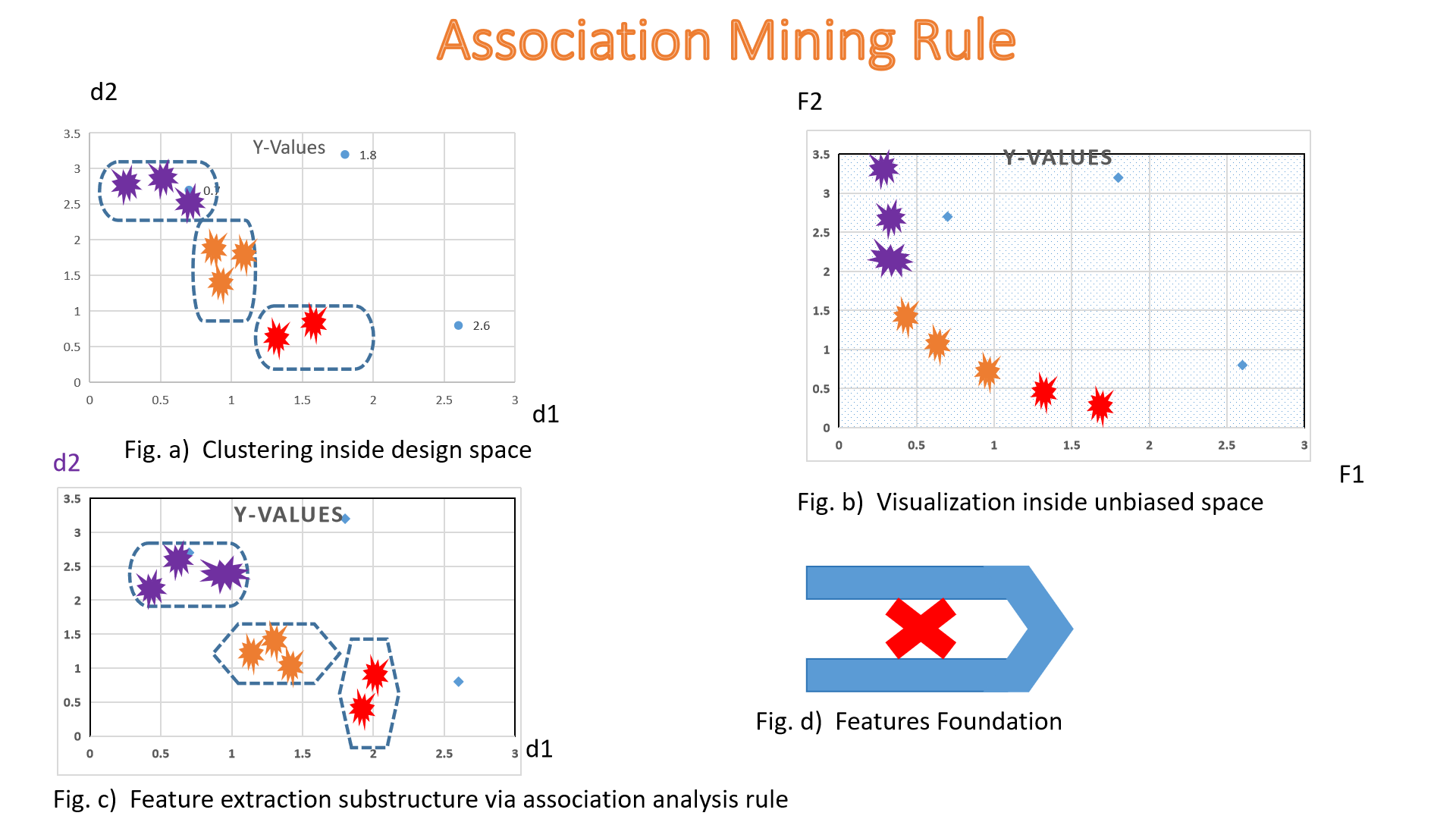
Let's take an example, if customers often shop for cheese and egg together, the shopkeeper can keep them in
accessibility to each other to encourage more sales. One more known application of association in
unsupervised
learning is in anomaly detection.
Let's be familiar with some other examples of Association rule ::
1. Market Basket Analysis.
2. Social network analysis.
3. Fraud Detection.
4. Recommendation systems.
5. Apriori algorithm
.
Let's see certain admired Association algorithms which comes under unsupervised learning ::
1. Learning Classifier System
2. Association Rule Learning
3. Apriori Algorithm
4. Singular-Value Decomposition
3. Dimensionality reduction
Let's discuss little bit about dimensionality reduction.
Dimensionality reduction is a key technique within unsupervised learning. It squeeze the features by finding
a smaller, different set of variables that capture what matters most in the original features, while
minimizing the loss of information.
Which algorithm is used for dimensionality reduction?
Principal Component Analysis (PCA)
In the context of Machine Learning (ML), PCA is an unsupervised machine learning algorithm that is used for
dimensionality reduction.
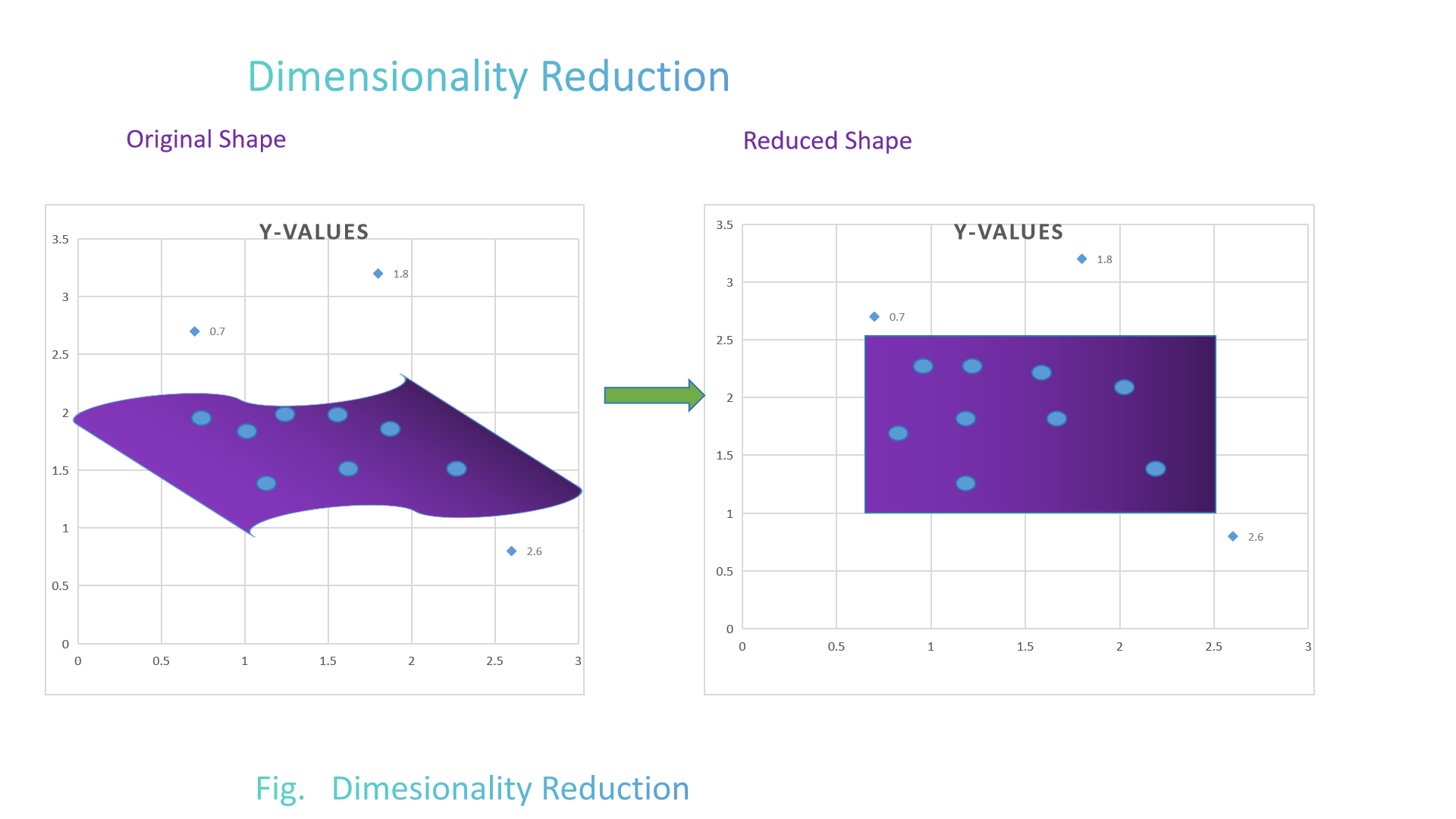 Here, two components present in dimensionality reduction ::
Here, two components present in dimensionality reduction ::
1. Feature selection - In general, we try to find a subset of the original set of variables, or features, to
get a
smaller subset which can be utilizd to model the problem. It generally presumes three ways-
a. Filter
b. Wrapper
c. Embedded
2. Feature extraction - Here, deduct the features in higher dimensional space to a lower dimension space,
i.e. a
space with lesser no. of dimensions.
Let's see the various methods utilized for dimensionality reduction include ::
1. Principal Component Analysis (PCA)
2. Linear Discriminant Analysis (LDA)
3. Generalized Discriminant Analysis (GDA)
Advantages of Dimensionality Reduction
1. It helps in features contraction, and thus diminish storage space.
2. It diminishes computation time.
3. It also assist to eliminate redundant features, if any.
4 Improved Visualization- High dimensional input is problamatic to visualize, and dimensionality reduction
techniques assist in visualizing the data in 2D or 3D, that help in better understanding and
analysis.
5. Overfitting Prevention - High dimensional input may conduct towards overfitting in machine learning
models, which
can
conduct to poor hypothesis performance. Dimensionality reduction can help in reducing the complexity of the
data, and thus prevent overfitting.
6. Feature Extraction - Dimensionality reduction can help in extracting important features from high
dimensional
data, which can be useful in feature selection for machine learning models.
7. Data Preprocessing - Dimensionality reduction can be used as a preprocessing step before applying machine
learning algorithms to reduce the dimensionality of the data and hence improve the performance of the model.
Disadvantages of Dimensionality Reduction
1. It may conduct to some amount of data loss.
2. PCA tends to find linear correlations between variables, which is
sometimes undesirable.
3. PCA fails in cases where mean and covariance are not enough to define datasets.
4.We may not know how many principal components to keep- in practice, some thumb
rules are applied.
4. Interpretability: The reduced dimensions may not be easily interpretable, and it may be difficult to
understand the relationship between the original features and the reduced dimensions.
5. Overfitting: In a bit instances, dimensionality reduction may lead to overfitting, especially when
the
number of components is chosen based on the training data.
6.Sensitivity to outliers: Any dimensionality reduction techniques are sensitive to outliers, which
can result in a biased representation of the data.
7. Computational complexity: Any dimensionality reduction techniques, such as manifold learning, can be
computationally intensive, especially when dealing with large datasets.
Let's implement the Python codes in unsupervised ways .....
Principal component analysis (PCA) is the process of computing the principal components then using them
to perform a change of basis on the data. In other words, PCA is an unsupervised learning dimensionality
reduction technique.
It’s useful to reduce the dimensionality of a dataset for two main reasons:
1. When there are too many dimensions in a dataset to visualize
2. To identify the most predictive n dimensions for feature selection when building a predictive model.
In this section, we will implement the PCA algorithm in Python on the Iris dataset and then visualize it
using matplotlib. Check out this DataCamp Workspace to follow along with the code used in this tutorial.
# firstly we need to import required libraries
import pandas as pd
from sklearn.datasets import load_iris # Dataset
from sklearn.decomposition import PCA # Algorithm
import matplotlib.pyplot as plt # Visualization
# Load the data
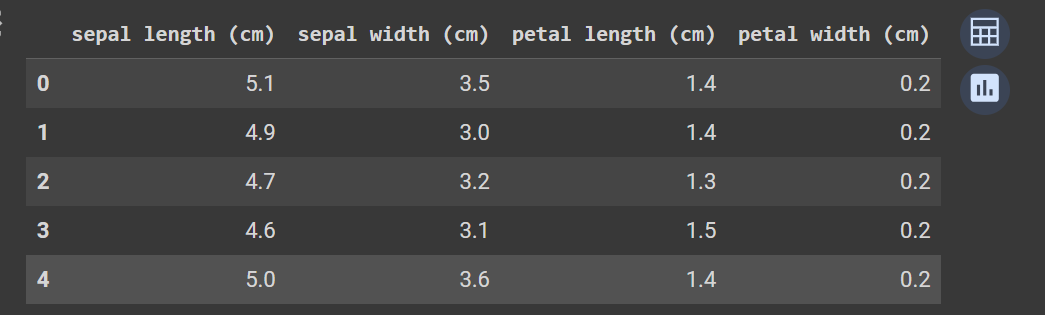
iris_data = load_iris(as_frame=True)
# Preview
iris_data.data.head()
result ::
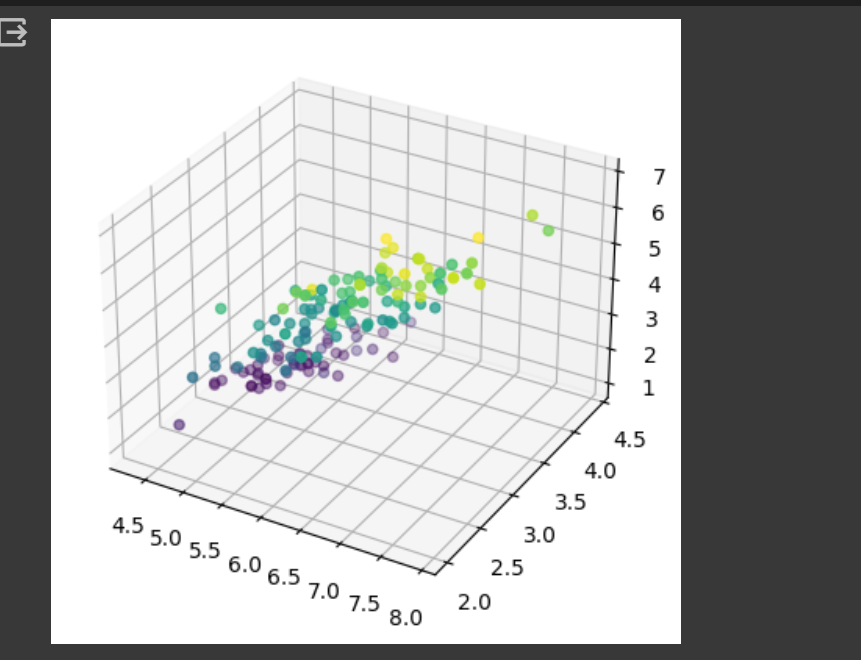
#now let's check the shape of our data
plt.rcParams["figure.figsize"] = [9.00, 4.00]
plt.rcParams["figure.autolayout"] = True
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
sepal_length = iris_data.data["sepal length (cm)"]
sepal_width = iris_data.data["sepal width (cm)"]
petal_length = iris_data.data["petal length (cm)"]
petal_width = iris_data.data["petal width (cm)"]
ax.scatter(sepal_length, sepal_width, petal_length, c=petal_width)
plt.show()
It’s quite difficult to get insights from this visualization because all of the inststances are jumbled
together since we only have access to one viewpoint when we visualize data in three dimensions in this
scenario.
With PCA, we can reduce the dimensions of the data down to two, which would then make it easier to visualize
our data and tell apart the classes.
result ::
#now let's check the required information we needed during analysis
# Instantiate PCA with 2 components
pca = PCA(n_components=2)
# Train the model
pca.fit(iris_data.data)
iris_data_reduced = pca.fit_transform(iris_data.data)
# Plot data
plt.scatter(
iris_data_reduced[:,0],
iris_data_reduced[:,1],
c=iris_data.target
)
plt.show()
result ::
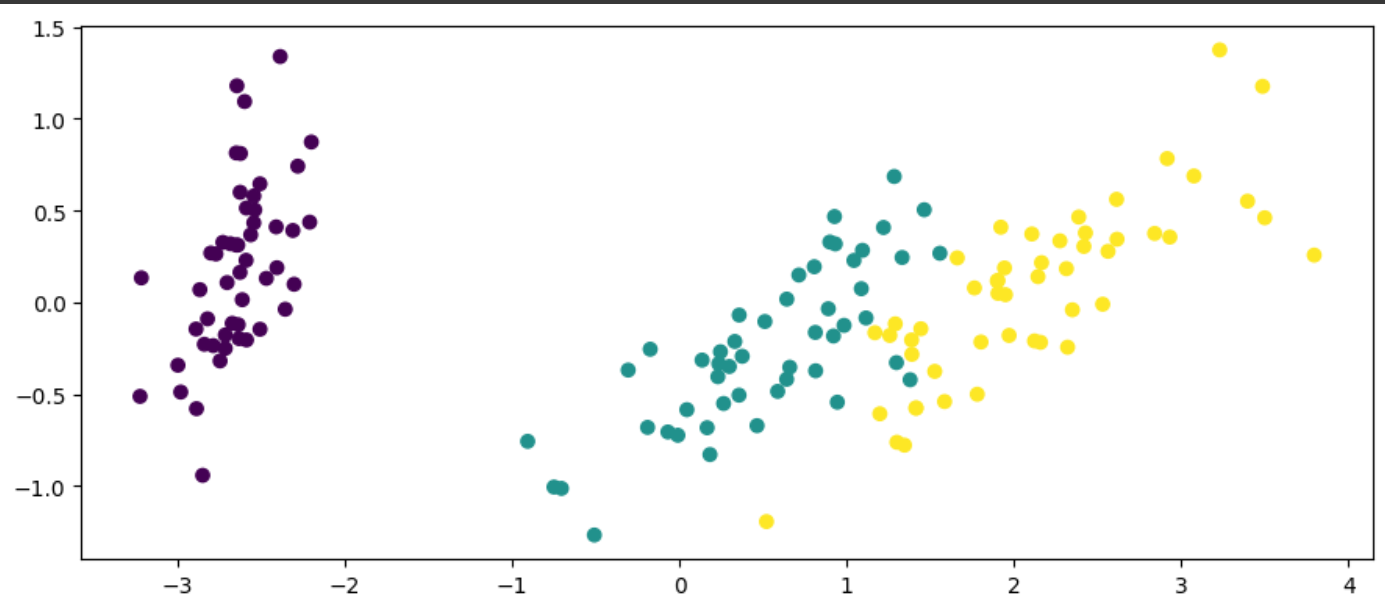
Final Thoughts K-means is the go-to unsupervised clustering algorithm that is easy to implement and trains
in next to no time. As the model trains by minimizing the sum of distances between data points and their
corresponding clusters, it is relatable to other machine learning models.
Applications of Unsupervised Machine Learning
Some other applications and advantages are written below ::
1. Speech recognition
Many apps or software programs that use speech recognition rely on unsupervised learning techniques.
Computing
professionals train speech recognition apps to understand basic human sounds, words and phrases. When you
download or install the app, it then begins to learn the specific sounds, intonations and pronunciations you
use
when issuing software commands. Over time, the speech recognition software improves its ability to recognize
your unique voice.
2. Natural language processing (NLP)
As per knowledge, Google News is known to clout unsupervised learning to categorize
articles
based on the similar tale from several news vent. For instance, the results of the football transfer window
can
all be categorized under football.
Image and video analysis. Visual Perception tasks such as object recognition leverage unsupervised learning.
3. Anomaly detection
Unsupervised learning is used to identify data points, events, and/or
observations that
deviate from a dataset's normal behavior.
Customer segmentation. Interesting buyer persona profiles can be created using unsupervised learning. This
helps
businesses to understand their customers' common traits and purchasing habits, thus, enabling them to align
their products more accordingly.
Recommendation Engines. Past purchase behavior coupled with unsupervised learning can be used to help
businesses
discover data trends that they could use to develop effective cross-selling strategies.
4. Splitting of data into groups based upon their similarity measure. Clustering methods are used to study
cancer gene expression data and predict cancer at early stages.
5. Neural Networks The principle that neurons that fire together wire together. In Hebbian Learningthe
connection is reinforced irrespective of an error, but is exclusively a function of the coincidence between
action potentials between the two neurons.
6. Deteccting of unusual data points in a data set. Example-
(a). Detect any sort of outliers in data from transportation and logistics companies, where anomaly
detection is
used to identify logistical obstacles or expose defective mechanical parts.
(b).Detect faulty equipment or breaches in security.
Fraud detection in transactions(a).
7. Object recognition: In the field of computer vision, it is utilized for visual perception tasks. It comes
in
really handy in image recognition.
8. Dimensionality Reduction allows us to lower the number of features in a dataset prevent overfitting. It
also
reduces the computational complexity of algorithms.
9. Utilizing the association rule to build recommender systems such as those of online and offline retail
stores. It is used to develop cross-selling strategies, hence facilitating the add-on recommendations during
checkout process.
10. Medical Imaging devices are required to do image detection, classification, and segmentation.
Unsupervised
learning is leveraged to make this feasible.
11. Building of a customer persona. Understanding the common traits and business client purchasing habits
helps
identify the customer persona, hence aligning the product goals a lot better.
Limitations of Unsupervised Learning
Let's see some of the limititions or disadvantages of unsupervised learning ::
1. Results may be unpredictable or difficult to understand.
2. Difficult to measure accuracy or effectiveness due to lack of predefined answers during training.
3. One of the major drawbacks of unsupervised learning is that we cannot get precise information on the data
sorting.
4. It can be costlier as often human intervention is required to correlate the patterns obtained to the
domain knowledge.
References
1. Garbade, Dr Michael J. (2018-09-12). "Understanding
K-means Clustering in Machine Learning". Medium. Retrieved 2019-10-31.
2. Wikipedia
3. IBM social sites
