Unsupervised Machine Learning Mastery
Let's analyze cluster data and implement unsupervised machine learning algorithms using Python for pattern recognition in unlabeled datasets.

📊 Fig: Unsupervised
Machine Learning Architecture
Python Implementation Guide
Working with pandas, seaborn, and numpy to discover patterns in unlabeled data through clustering algorithms, achieving higher accuracy through visualization.
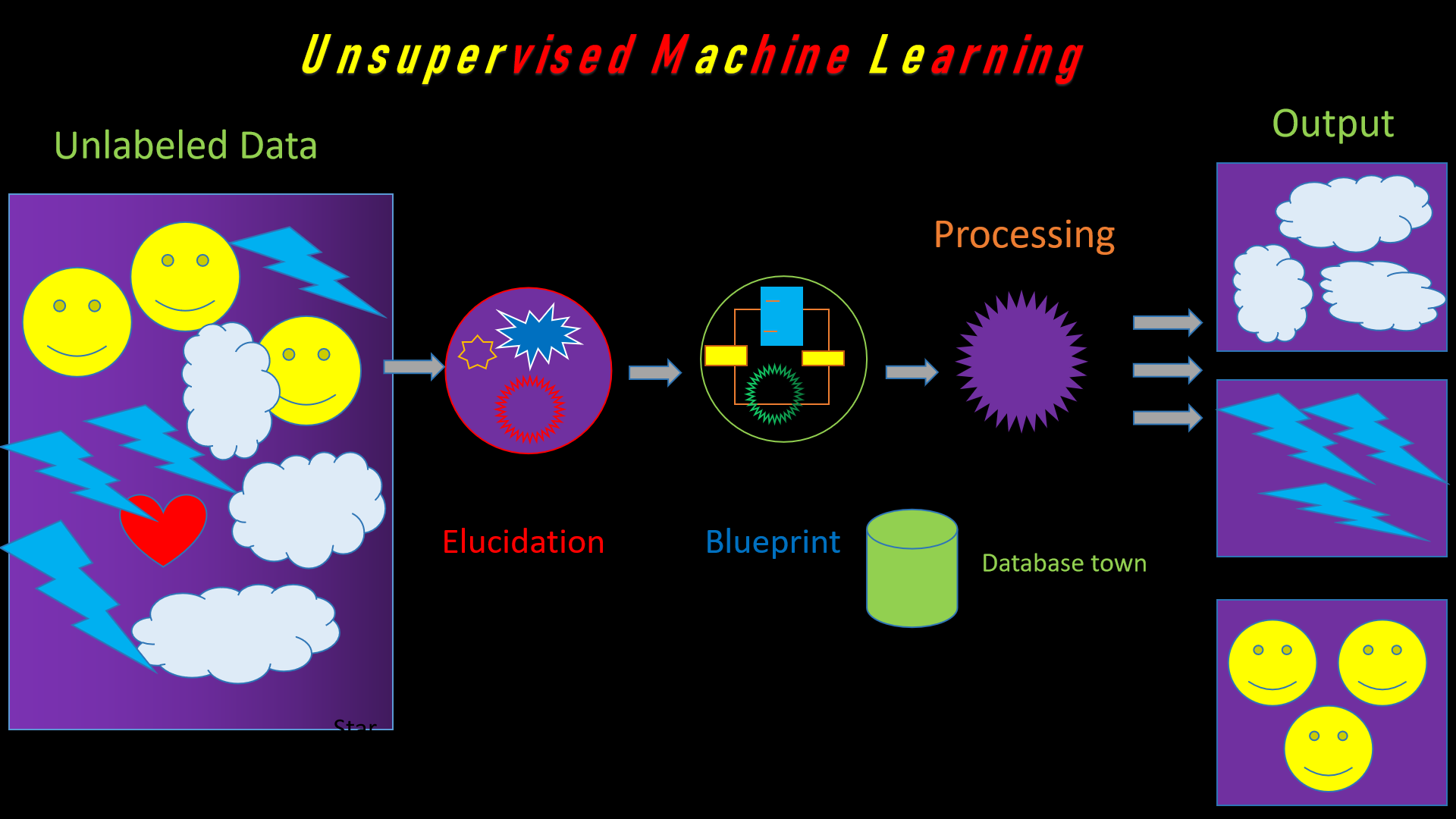
⚙️ Fig: Unsupervised
Learning Mechanism
Core Algorithms
1. K-Means Clustering
Clustering groups data points by similarities. K-Means partitions data into K clusters by minimizing variance within each cluster.
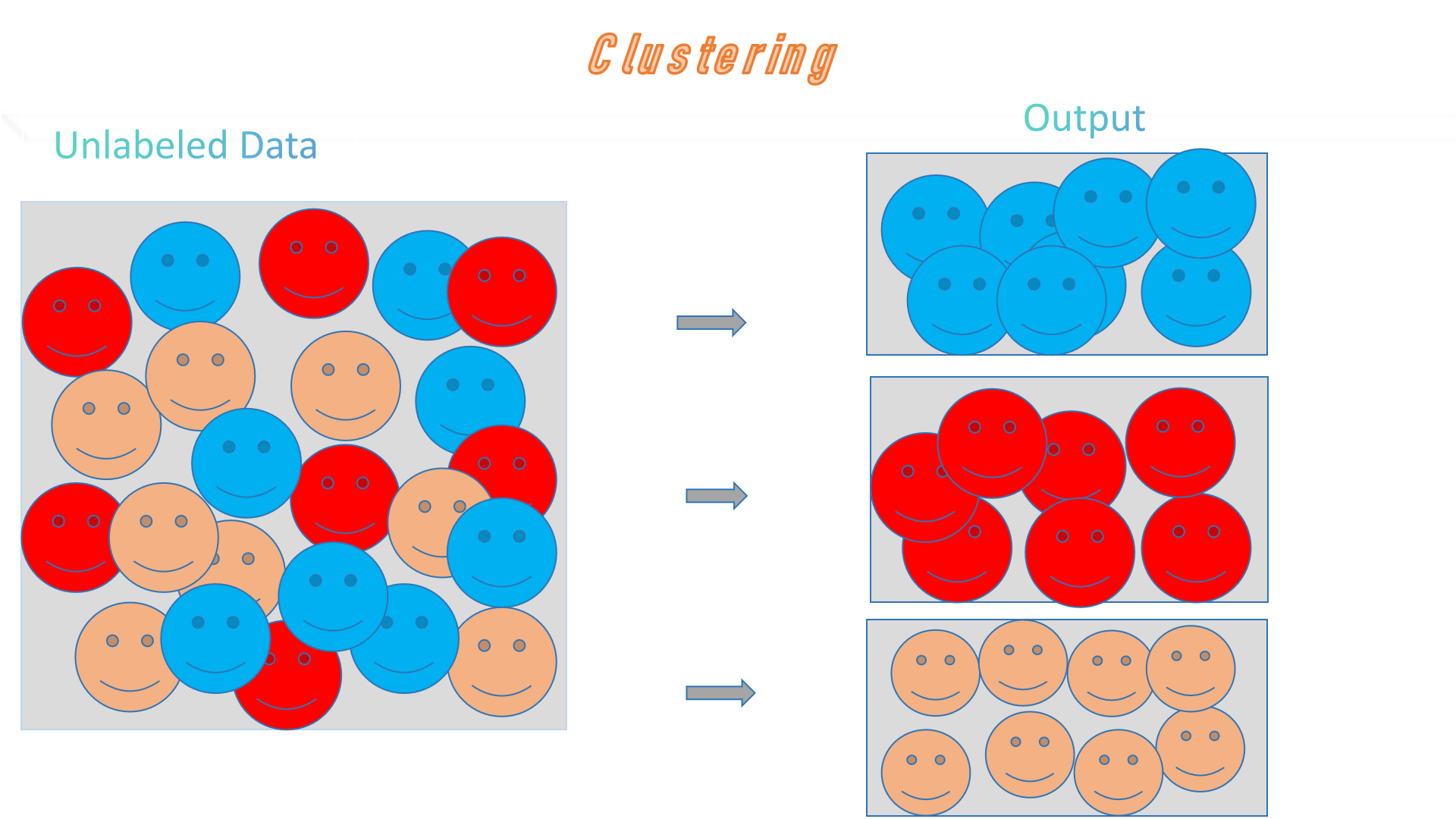
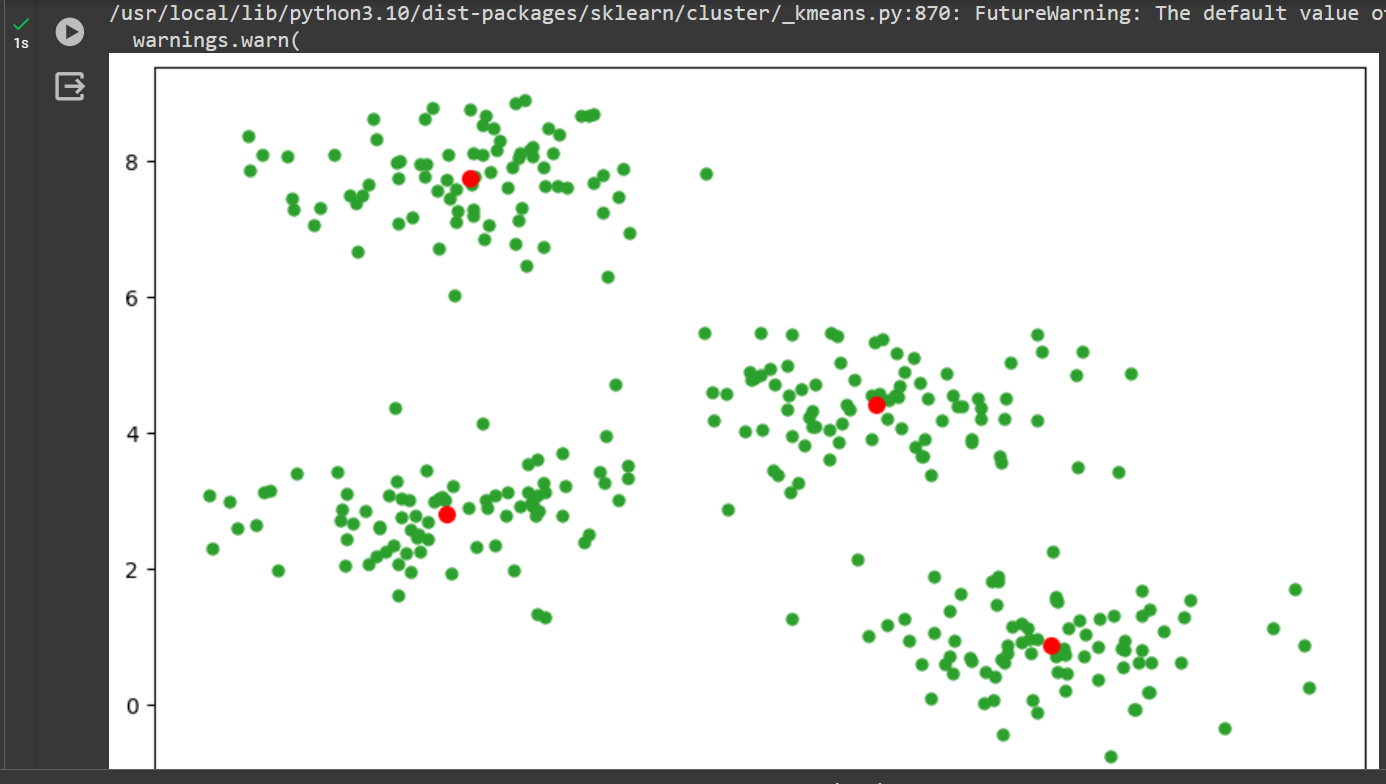
✅ Live Demo: Test the K-Means code in the right column!
🚀 Python Implementation
# K-Means Clustering Demo
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
n_clusters = 4
X, _ = make_blobs(n_samples=333, centers=n_clusters, cluster_std=0.60, random_state=0)
kmeans = KMeans(n_clusters=n_clusters, random_state=0, max_iter=111).fit(X)
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1], c=kmeans.labels_, s=25, cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1],
c='red', s=100, marker='X', label='Centroids')
plt.title("🧠 K-Means Clustering Results")
plt.legend()
plt.show()
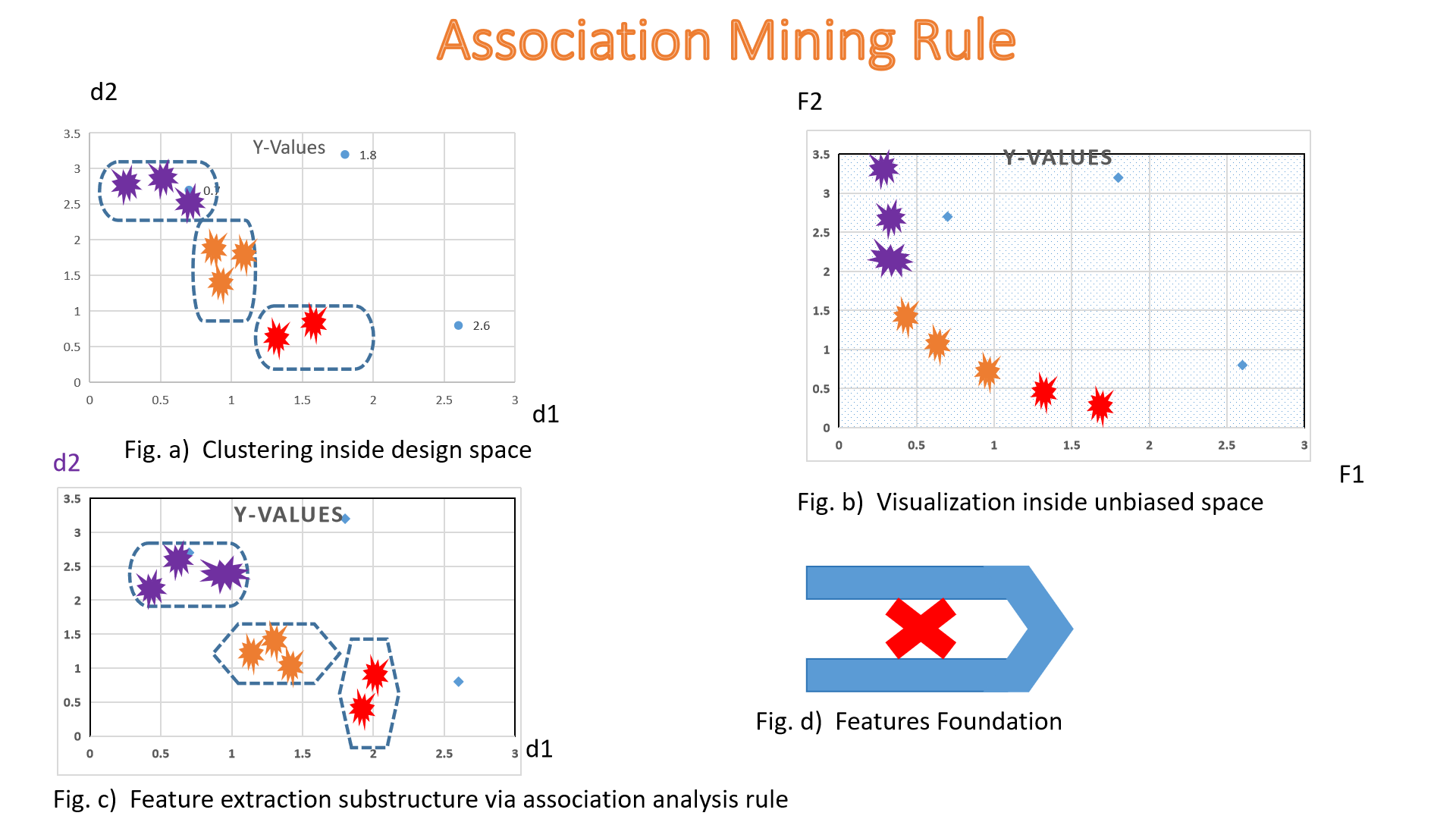
2. Association Rules
Discover relationships between variables in large datasets. Used in market basket analysis and recommendation systems.
3. Dimensionality Reduction (PCA)
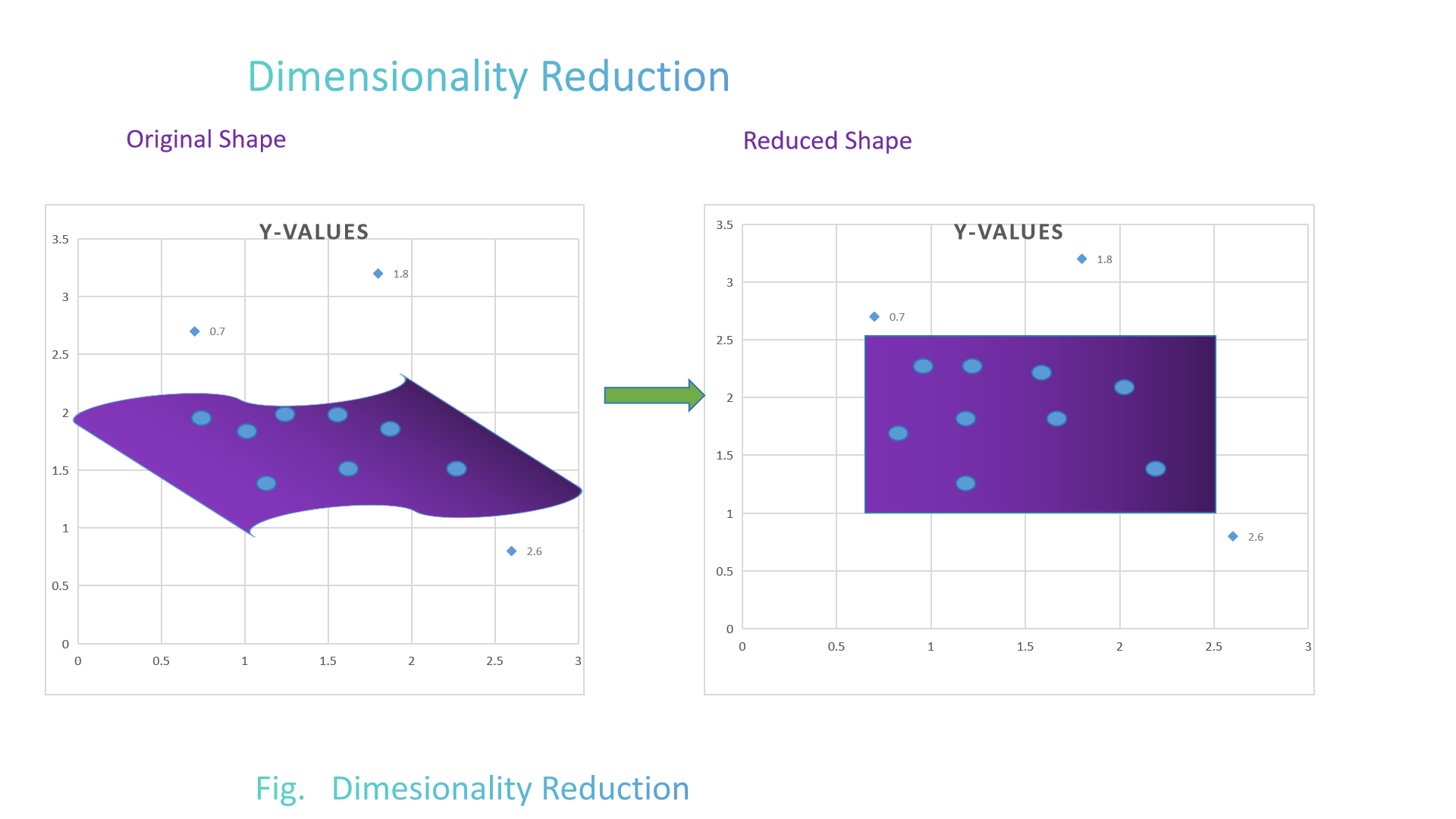
🔥 Copy PCA code to test column →
Real-World Applications
- 🎯 Anomaly Detection & Fraud Prevention
- 👥 Customer Segmentation
- 🩺 Medical Imaging Analysis
- 📱 Recommendation Systems
💻 Interactive Code Tester
# Paste your Python code here 👇
# Try the K-Means or PCA examples!
import numpy as np
print("AI Legend Code Playground")
print("Ready for unsupervised ML experiments!")
# Example: Simple clustering
data = np.random.rand(10, 2)
print("Sample data shape:", data.shape)
print("Test your code below ⬇️")