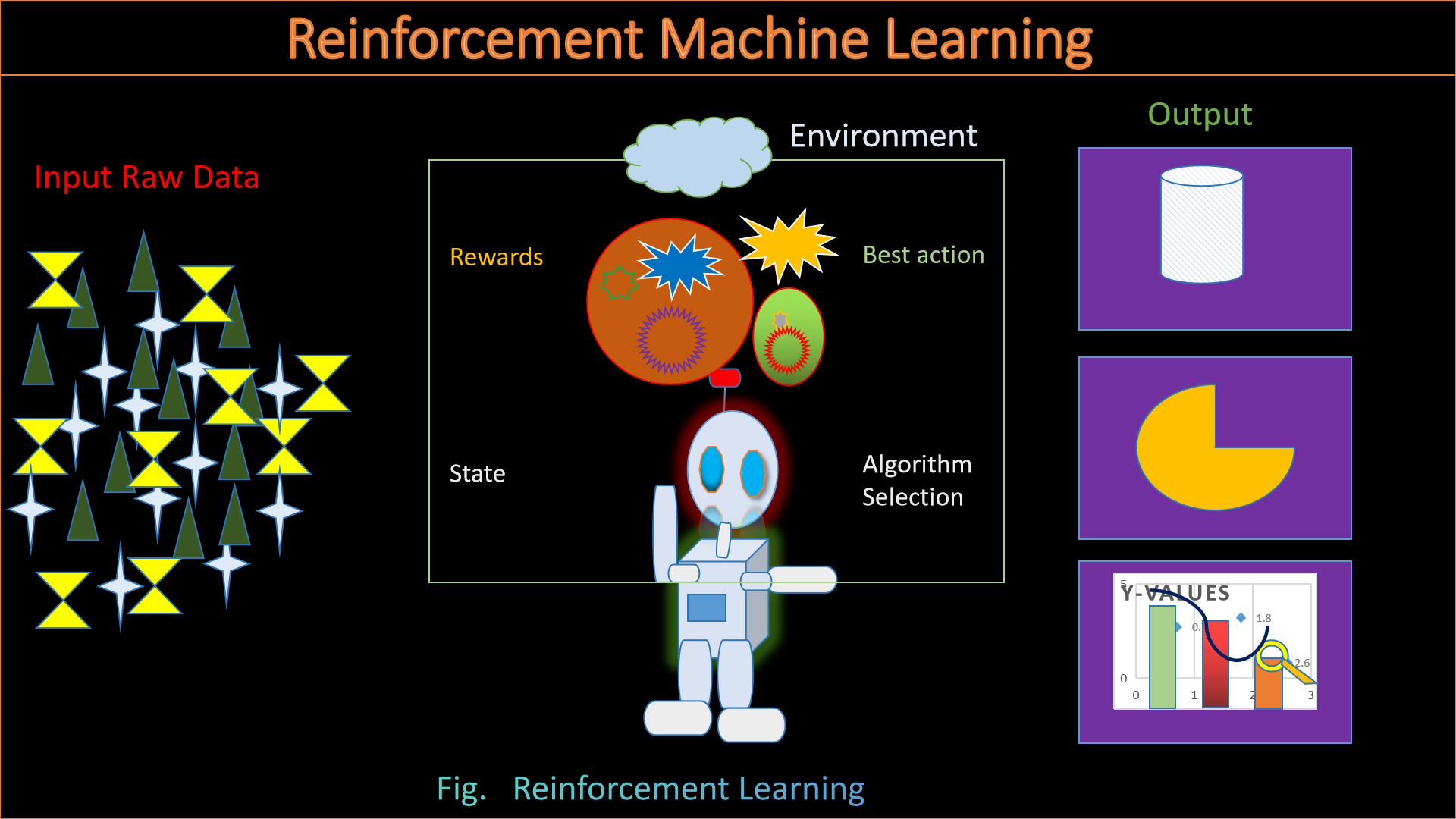
Reinforcement Machine Learning...
Let's analyze the action oriented ML algorithm whether achieving penalty or bonanzas and also its
implementation on some of the algorithms of the reinforcement machine
learning
techniques via Python...
Let's study the Python codes in reinforcement ways .....
So, we are working in Python code along with pandas, seaborn, numpy etc. libraries to determine
prediction
on the basis of bonanzas with positive action or penalty with every wrong action taken by gadgets or
software respectively.
Now let's discuss little bit about Reinforcement learning, it is a machine
learning (ML) methodology generally edify application for decision making to attain the nearly all the
optimal upshot. It
mimics the trial-and-error learning procedure which in general, humanoid utilizes to attain their
target. Software actions
which efforts respecting our desired output, we can say, reinforced, although measures that belittle
from the target generally disregard.
RL algorithms using a bonanza-and-indemnity paradigm as they process data. They learn from the feedback
of
each action and self-discover the best processing paths to achieve final outcomes. The algorithms are
also capable of delayed gratification. The best overall strategy may require short-term sacrifices, so
the best approach they discover may include some indemnity or backtracking along the way. RL is a
powerful method to help artificial intelligence (AI) systems achieve optimal outcomes in unseen
environments.
How does Reinforcement Learning works?...
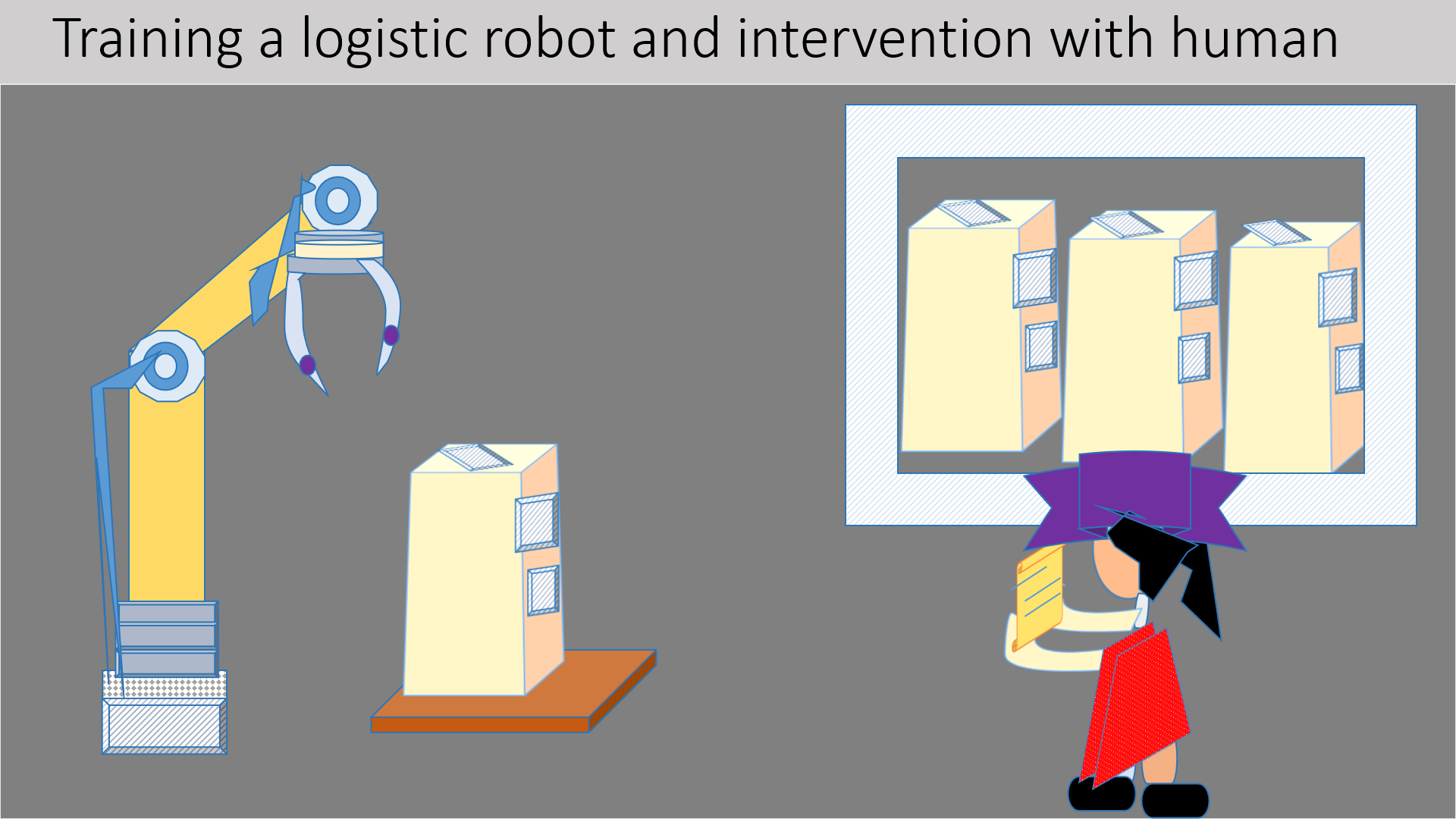 Generally reinforcement learning utilized to train any logistics robot, here agent said to be robot which
performs in a
depot environment. It picks numerous actions which generally encounter with feedback, including prize and
particulars or examination from the context. Each n every little info through response helps the agent to
thrive any approach for
further achievements.
Generally reinforcement learning utilized to train any logistics robot, here agent said to be robot which
performs in a
depot environment. It picks numerous actions which generally encounter with feedback, including prize and
particulars or examination from the context. Each n every little info through response helps the agent to
thrive any approach for
further achievements.
Rather than referring to a specific algorithm, the field of reinforcement learning is made up of several
algorithms that take somewhat different approaches.
Benefits of reinforcement learning
Reinforcement learning is to puzzle out several complex problems which generally, traditional ML
algorithms
crash to direct. RL is
known for its aptness to accomplish the tasks autonomously via traversing utterly probabilities and
trajectory, in that way
sketching parallelism to artificial general intelligence (AGI).
The key benefits of RL are:
1. Focuses on the long-term goal:
Here we'll focus on classic ML algorithms split problems into subproblems and direct them
discretely without examine the key problem. Nonetheless, RL commonly regards to accomplish long-term goal
without splitting the task into sub-tasks, by that way boosting the rewards.
2. Easy data collection process:
Now, here RL does not involve an independent data collection process. As the generator
operates within the environment, training data is dynamically collected through the generator’s response and
experience.
3. Operates in an evolving & uncertain environment:
In this condition, the learning fabricated on the basis of malleable architecture as per circumstances.
It also very flexible to alter from new surroundings via interaticting with it and can do implementation
well.
How Does Reinforcement Learning Work?
The working principle of reinforcement learning is based on the bonanza episode. Let’s understand the RL
mechanism with the help of an example.
Now we consider a pet (like a bird) to teach particular mannerism.
Just when our bird don't know human language, necessity to embrace a bit differ approach.
We design a situation where the bird performs a specific task and offer a bonanza (such as a treat) to the
bird alright.
Now, whenever the bird fronts a similar situation, tries to perform the same action that had previously
earned him the bonanza with more enthusiasm.
The bird thereby ‘learns’ from its rewarding experiences and repeats the actions as it now knows ‘what to
do’
when a particular situation arises.
On similar lines, the bird also becomes aware of the things to avoid if it encounters a specific situation.
Use case ....
In the above case,
Let's consider that pet(parrot) behaves like a generator which lives inside the house, said to be an
environment. Here, the position mention to the parrot’s loafy circumstances, generally transpose to fly when
we utter a certain word.
The transition from launging to migrant transpires when the generator reacts to our word as long as in the
context.
Here, the policy allows agents to take action in a particular circumstances and expect a better consequence.
After the pet alter towards next circumstances (fly or walk), it gets a bonanza (parrot food).
The reinforcement learning workflow involves training the generator while considering the following key
factors:
~ Environment
~ Bonanzas
~ Generator
~ Training
~ Deployment
Let’s understand each one in detail.
Step I: Generate an environment
The RL process begins by defining the environment in which the generator stays active. The environment may
refer
to an actual physical system or a simulated environment. Once the environment is determined, experimentation
can begin for the RL process.
Step II: Specify the bonanzas
In the next step, we need to define the bonanza for the generator. It acts as a performance metric for the
generator
and allows the generator to evaluate the task quality against its goals. Moreover, offering appropriate
bonanzas
to the generator may require a few iterations to finalize the right one for a specific action.
Step III: Define the generator
Once the environment and bonanzas are finalized, we can create the agent that specifies the policies
involved, including the RL training algorithm. The process can include the following steps:
Use appropriate neural networks or lookup tables to represent the policy
Choose the suitable RL training algorithm.
Step IV: Train/Validate the generator
So let us start training and validating our generator to fine-tune the training policy. Also, focus on the
bonanza framework RL design
policy architecture and continue the training process. Reinforcement training is tame and takes minutes to
days deploy on the end application. In consequence, for a complex set of applications,speedy training is
accomplished via
manipulating a apparatus architecture whither several CPUs, GPUs, and computing systems run in parallel.
Step V: Implement the policy
Finally implimentation will take place for that reason need to enable reinforcement policy system serves
just like the decision-making component deployed using C, C++, or CUDA
development code.
Althogh implementing these policies, revisiting the initial stages of the RL workflow is sometimes essential
in situations when optimal decisions or results are not achieved.
The factors mentioned below may need fine-tuning, followed by retraining of the agent:
Reinforcement algorithm configuration
Bonanzas interpretation
Action / state signal detection
Environmental variables
Training structure
Policy framework
See More: Narrow AI vs. General AI vs. Super AI: Key Comparisons
Reinforcement Learning Algorithms
Reinforcement Learning Algorithms are fundamentally divided into two types: model-based and model-free
algorithms. Sub-dividing
these further, algorithms fall under on-policy and off-policy types.
Well, in a model-based algo, nearby endurea a interpret reinforcement model that learns from the current
state, actions, and
state transitions occurring due to the actions. Thus, these types store state and action data for future
reference. As an alternative, model-free algorithms operate on trial and error methods, as a result
terminating the reqirement of cache such as state and action data inside the memory of gadgets right.
On-policy and off-policy algorithms can be better understood with the help of the following mathematical
notations:
The letter ‘s’ represents the state, the letter ‘a’ represents action, and the symbol ‘π’ represents the
probability of determining the reward. Q(s, a) function is helpful for the prediction process and offers
future rewards to the agents by comprehending and learning from states, actions, and state transitions.
Thus, on-policy uses the Q(s, a) function to learn from current states and actions, while off-policy focuses
on learning [Q(s, a)] from random states and actions.
Moreover, the Markov decision process emphasizes the current state, which helps predict future states rather
than relying on past state information. This implies that the future state probability depends on current
states more than the process that leads to the current state. Markov property has a crucial role to play in
reinforcement learning.
Schema of Reinforcement Learning
1. Generate the good surrounding
So basically we need to determine the surrounding with which our reinforcement learning delegate could
perform, counting the collaboration between delegates and surroundings right. The surrounding can be any of
them, whether miniature prototype
or anatomic apparatus.Althogh miniature prototype will be well for the first time user because of its
beneficial nature for not being danger as for experimental things.
2. Determine the bonanza
After that, specify the bonanza signal that the generator utilizes to measure its performance against the
task objective and
how this signal is deliberateed from the environment. Bonanza customizing possibly tricky and may requisite
a little-bit
iterations to get it right.
3. Create the generator
Then you create the agent, which consists of the policy and the reinforcement learning training algorithm.
So you need to:
a) Pick out a strategy to represent the policy (such as using neural networks or look-up tables).
b) Sort out an appropriate training algorithm. Unalike rendering are frequently secured to specific
sort of training algorithms. But in general, most modern reinforcement learning algorithms rely on
neural networks as they are good candidates for large state/action spaces and complex problems.
4. Train and validate the generator
We need to layout our training options (such as terminate criteria) and train the generator to caliberate
the policy. Be certain whatever the training policy is validating to the training ends alright.
At a pinch, readdress the design alternatives as the bonanza signal
and policy layout and train afresh. Reinforcement learning is universally known to be sample inefficient;
training be able to grab anywhere from seconds to weeks rely on the requisition. For complex applications,
parallelizing training on multiple CPUs, GPUs, and computer clusters will speed things up (Figure).
5. Deploy the policy
Now let's deploy the trained policy description using, for example, generated C/C++ or CUDA code. At this
point,
the policy is a standalone decision-making system.
So, training any generator utilizing reinforcement learning is an iterative process. Decisions and results
in later
stages can require you to return to an earlier stage in the learning workflow. For example, if the training
process does not converge to an optimal policy within a reasonable amount of time, you may have to update
any of the following before retraining the agent:
~ Training settings
~ Reinforcement learning algorithm configuration
~ Policy rendering
~ Bonanza signal depiction
~ Action and observation signals
~ Environment potent
Algorithms
Let's study some of the algorithms present in reinforcement machine
learning .....
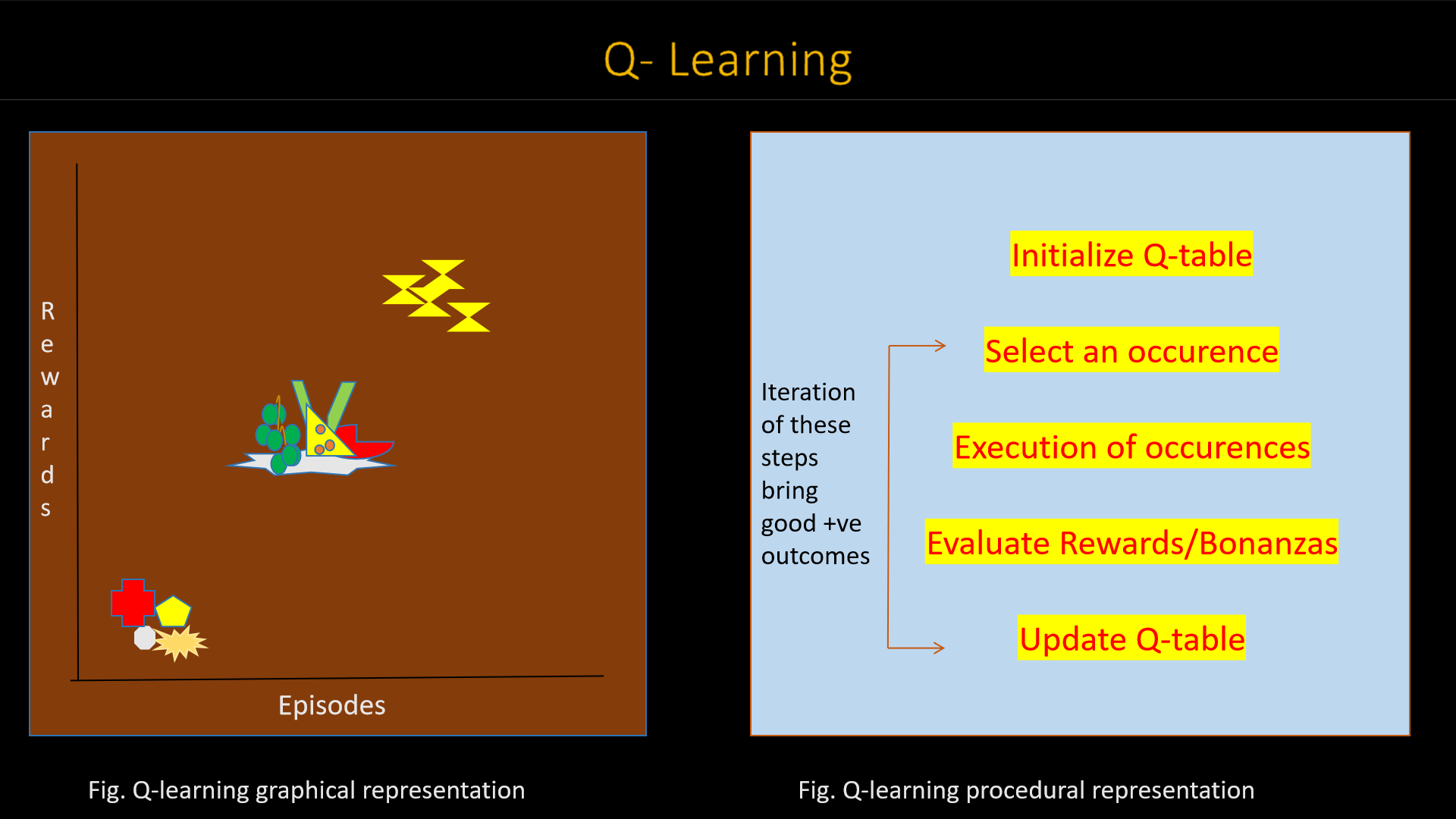
1. Q-learning
What is Q-learning?... How it is used?... Well, Q-learning is such kind of algorithm involves with the
vanishing-approach and
wobbly-scheme which generally learns from haphazards occurences(we can say, greedy policy) respectively.
So basically, in Q-learning 'Q' ally with the status of voyage that generally amplify the bonanzas initiated
via the
algorithmic process.
Generally, the Q-learning algorithm utilizes a technique to cache the drew treasures said to be
reward/payoff matrix mostly used in game theory .
Let's discuss any example for better understanding, for bonanza 50, a
reward matrix is constructed that assigns a value at position 50 to denote reward 50. These values are
updated using methods such as policy iteration and value iteration.
Policy iteration refers to policy improvement or refinement through actions that amplify the value function.
In a value iteration, the values of the value function are updated. Mathematically & graphically, Q-learning
is
represented by the formula and graph:
 Q(s,a) = (1-α).Q(s,a) + α.(R + γ.max(Q(S2,a)).
Q(s,a) = (1-α).Q(s,a) + α.(R + γ.max(Q(S2,a)).
Where,
alpha = learning rate,
gamma = discount factor,
R = reward,
S2 = next state.
Q(S2,a) = future value.
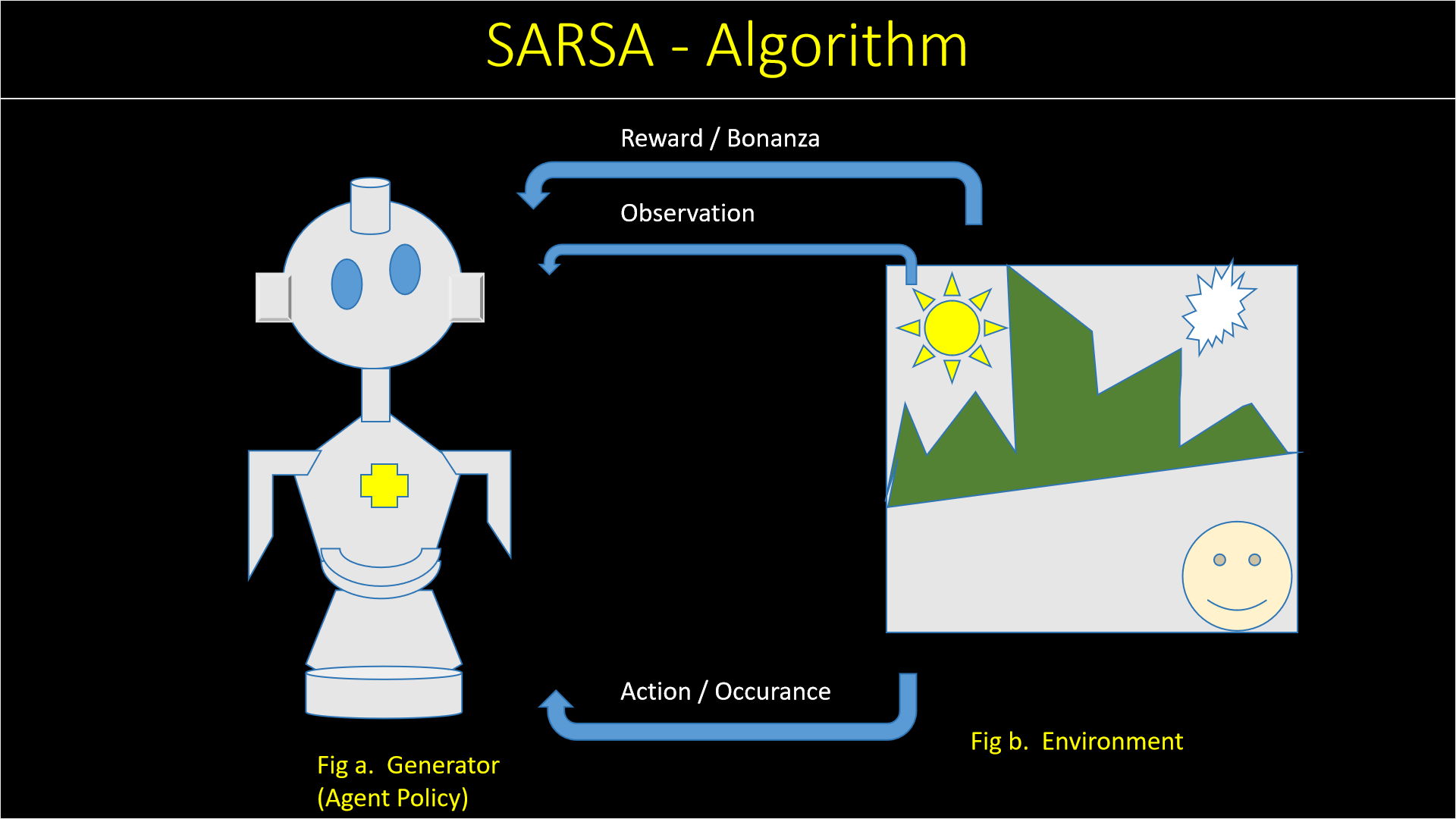
2. SARSA
Well it is such kind of reinforcement learning where environment playing vital role to accomplish the task
alright.
SARSA stands for the State-Action-Reward-State-Action algorithm is generally an on-policy technique.
Thatswhy, does
not stick with the greedy loom of Q-learning.
Here our Generator intarcting with its environment to perform action accordingly. It learns and recognizes
the current situation or we can say the pattern to choose wisely and receive a numerical bonanza i.e.
to capable of reverting the reward from the environment. The reinforcement learning pursue to boost the
appraise the generator's gross bonanzas catche via interacting with the environment respectively.
Mostly this algo used in Generative AI. Most common library used in SARSA algorithm is OpenAI Gym.
It is an open surce library used in Python for developing and comparing the reinforcement learning
algorithm.
 So basically SARSA algorithm grasp a blueprint which generally assured an exploration and exploitation,
along with which generally utilized in a diversity
of implimentations, together with medical field, game playing, robotics and decision making gadgets etc.
Nevertheless, poin to be noted,
that the convergence of the SARSA algorithm can be slow, especially in large state spaces, and there are
that the alternative reinforcement learning algorithms possibly fresh potent in certain circumstancse
respectively.
So basically SARSA algorithm grasp a blueprint which generally assured an exploration and exploitation,
along with which generally utilized in a diversity
of implimentations, together with medical field, game playing, robotics and decision making gadgets etc.
Nevertheless, poin to be noted,
that the convergence of the SARSA algorithm can be slow, especially in large state spaces, and there are
that the alternative reinforcement learning algorithms possibly fresh potent in certain circumstancse
respectively.
3. Deep Q-network (DQN)
Let's discuss little bit about dimensionality reduction.
Unlike Q-learning and SARSA, deep Q-network utilizes a neural network and does not depend on 2D arrays.
Q-learning algorithms are inefficient in predicting and updating the state values they are unaware of,
generally unknown states.
Hence, in DQN, 2D arrays are replaced by neural networks for the efficient calculation of state values and
values representing state transitions, thereby speeding up the learning aspect of RL.
.png)
.png)
.png)
.png)
.png)
Advantages of Reinforcement Learning
1. As Reinforcement learning literally playing a vital role in our life as it is capable of solving highly
cmplex problem where human lack or less advantageous nor a conventional techniques too.
2. If we talk about the error/noise reduction it plays a vital role to train our model fine tune to reduce
error.
3. The most fascinating thing about Renforcement learning is as it gather its own data from the surroundings
via interaction within.
4. Reinforcement learning can handle environments that are non-deterministic, meaning that the outcomes of
actions are not always predictable. This is useful in real-world applications where the environment may
change over time or is uncertain.
5. Reinforcement technique can deal with the mess simultaneously with fine tune whether
decision making, control, and optimization.
6. Reinforcement learning is a flexible approach that can be combined with other machine learning
techniques, such as deep learning, to improve performance.
Disadvantages of Reinforcement Learning
As of now, if there is have advantages then so obvious there will be disadvantage. So let's discuss some of
them ->
1. It is not preferable to utilize Reinforcement learning to resolve normal query as it learn from the its
own environment and then take action accordingly right.
2. As reinforcement technique requisites a bulk of data to gather info for further computation. Like we can
see self driving car, if we'll not give the to the point instructions then there having high chances of
accidents.
3. Reaward / Bonanza calibre playing vital role to provide the better or worst performance of agent. What
if, the reward function
is poorly designed, the agent may not learn the desired behavior.
4. Reinforcement learning can be difficult to debug and interpret. It is not always clear why the agent is
behaving in a certain way, which can make it difficult to diagnose and fix problems.
Limitations
As per researchers and scientists, Reinforcement learning theory reflecting the focus on behavioural concept
over mental internal state.
At the first stage, a psychologist B.F. Skinner flourished the reinforcement theory, generally states that
rewarded behaviors are probable to be iterated, although maltreat behaviors are probable to halt right.
References
1. C.E. Brodely and M.A. Friedl (1999).
Identifying and Eliminating Mislabeled Training Instances, Journal of Artificial Intelligence
Research 11, 131-167. (http://jair.org/media/606/live-606-1803-jair.pdf)
2. Wikipedia
3. IBM social sites
